
图像分割
点、线和边缘检测
背景知识
- 导数
- 一阶导数
$$ \frac{\partial f}{\partial x} = f(x+1) - f(x) $$ - 二阶导数
$$ \frac{\partial^2 f}{\partial x^2} = f(x-1) - 2f(x) + f(x+1) $$
- 一阶导数
- 结论
- 一阶导数通常产生粗边缘
- 二阶导数对精细细节(如细线、孤立点和噪声)有更强的响应
- 二阶导数在灰度斜坡和台阶处会产生双边缘响应
- 二阶导数的符号可以判断边缘的过渡是由亮到暗(-)还是由暗到亮(+)
孤立点检测
点检测应该以二阶导数为基础,即拉普拉斯:
$$ \bigtriangledown^2 f(x,y) = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2} $$
其离散形式:
$$ \bigtriangledown f(x, y) = f(x+1, y) + f(x-1, y) + f(x, y+1) + f(x, y-1) - 4f(x, y) $$
$$ \begin{bmatrix}
0 & 1 & 0 \
1 & -4 & 1 \
0 & 1 & 0
\end{bmatrix} $$
若滤波器在这一点的响应的绝对值超过一个阈值,则我们说在核的中心位置检测到了一个点。
线检测
对于线检测同样可以使用拉普拉斯核,但要注意处理二阶导数的双线效应。
$$ \begin{bmatrix}
1 & 1 & 1 \
1 & -8 & 1 \
1 & 1 & 1
\end{bmatrix} $$
如果负值直接取绝对值,会导致线宽度加倍。更合适的方法是只使用正值。
上面的拉普拉斯核是各向同性的,因此其响应与方向无关。如果要检测规定方向的线,可以用下面的核。
| $\begin{bmatrix}-1 & -1 & -1 \2 & 2 & 2 \-1 & -1 & -1\end{bmatrix}$ | $\begin{bmatrix}2 & -1 & -1 \-1 & 2 & -1 \-1 & -1 & 2\end{bmatrix}$ | $\begin{bmatrix}-1 & 2 & -1 \-1 & 2 & -1 \-1 & 2 & -1\end{bmatrix}$ | $\begin{bmatrix}-1 & -1 & 2 \-1 & 2 & -1 \2 & -1 & -1\end{bmatrix}$ |
|---|---|---|---|
| 水平 | +45° | 垂直 | -45° |
边缘检测
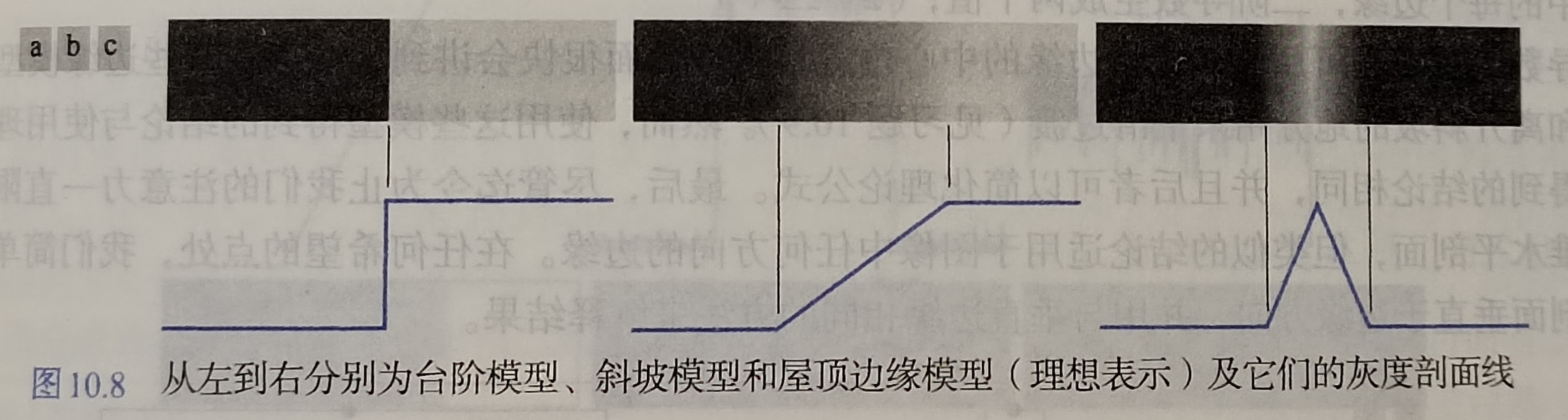
- 边缘模型
- 台阶边缘模型:在1个像素的距离上发生两个灰度级间理想的过渡,即这两个灰度级过渡时存在一条较为明显的分界线
- 斜坡边缘模型:在实际情况中,数字图像可能被模糊或者是带有噪声,此时的边缘模型更接近斜坡边缘模型,灰度级的过渡存在一个较宽的区域,也就不存在一个较为明显的分界线
- 屋顶边缘模型:该模型是通过一个区域的线的模型,边缘的基底(宽度)由该线的宽度和尖锐度决定
零灰度轴和二阶导数极值之间的连线交点,称为该二阶导数的零交叉点或过零点。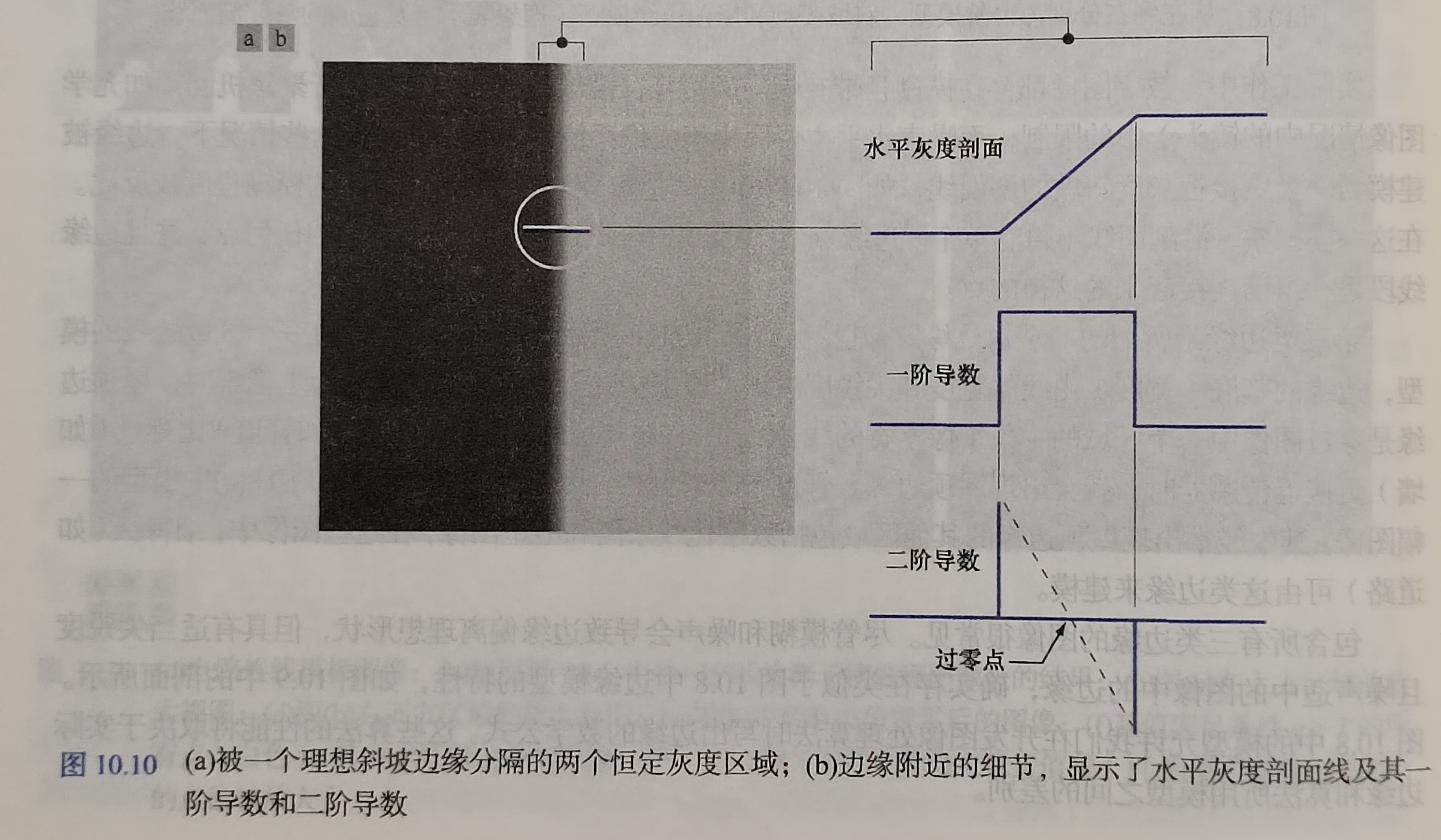
边缘二阶导数的附加性质:
- 对图像的每个边缘,二阶导数生成两个值
- 二阶导数的过零点可用于确定粗边缘的中心位置
边缘检测的三个基本步骤
- 为了降噪,对图像进行平滑处理
- 检测边缘点,从图像中提取可能是边缘点的所有点
- 边缘定位,从候选边缘点中选择组成边缘的点
基本边缘检测
为了寻找边缘,可以用一阶导数或二阶导数来检测边缘。
- 图像梯度
- 梯度算子
- 罗伯特算子
$$ \begin{bmatrix}-1 & 0\0 & 1\\end{bmatrix}
\begin{bmatrix}0 & -1\1 & 0\\end{bmatrix}$$ - Prewitt 算子
$$
\begin{bmatrix}
-1 & -1 & -1 \
0 & 0 & 0 \
1 & 1 & 1
\end{bmatrix}
\begin{bmatrix}
-1 & 0 & 1 \
-1 & 0 & 1 \
-1 & 0 & 1
\end{bmatrix}
$$ - Sobel 算子
$$
\begin{bmatrix}
-1 & -2 & -1 \
0 & 0 & 0 \
1 & 2 & 1
\end{bmatrix}
\begin{bmatrix}
-1 & 0 & 1 \
-2 & 0 & 2 \
-1 & 0 & 1
\end{bmatrix}
$$
- 罗伯特算子
上述模板用于在每个像素位置处得到梯度分量。然而在计算梯度时,平方和开根需要大量的计算开销,往往使用绝对值来近似梯度幅值:
$$ M(x,y) = |g_x|+|g_y| $$
上式不仅计算简单而且能够保留灰度级的相对变化。为此付出的代价是,滤波器不再是各向同性(旋转不变)的。但对 Prewitt 和 Sobel并不是问题,因为这些核只对垂直边缘和水平边缘给出各向同性的结果。
更先进的边缘检测技术
Marr-Hildreth 边缘检测子
其核心思想是通过高斯滤波平滑图像,然后使用拉普拉斯变换检测边缘,最后通过零交叉点来确定边缘位置。具体步骤如下:- 高斯滤波:平滑图像,减少噪声。
- 拉普拉斯变换:检测图像的二阶导数,找出潜在的边缘位置。
- 零交叉点检测:确定边缘的确切位置。
高斯拉普拉斯函数(LoG):
- 二维高斯函数
$$G(x, y) = e^{-\frac{x^2 + y^2}{2\sigma^2}}$$ - 拉普拉斯变换
$$ \nabla^2 = \frac{\partial^2}{\partial x^2} + \frac{\partial^2}{\partial y^2} $$ - LoG
将高斯函数带入拉普拉斯得到下式:
$$ \nabla^2 G(x, y) = ( \frac{x^2 + y^2 - 2\sigma^2}{\sigma^4}) e^{-\frac{x^2 + y^2}{2\sigma^2}} $$
下面的核与 LoG 函数近似(通常使用该核的负核)
$$
\begin{bmatrix}
0 & 0 & -1 & 0 & 0 \
0 & -1 & -2 & -1 & 0 \
-1 & -2 & 16 & -2 & -1 \
0 & -1 & -2 & -1 & 0 \
0 & 0 & -1 & 0 & 0 \
\end{bmatrix}
$$
Canny 边缘检测子
- 高斯滤波
平滑图像,减少噪声和细节,防止这些无关信息在后续步骤中被误检为边缘。 - 计算图像梯度
计算滤波后图像的梯度幅值和方向角度,以便后续步骤进行边缘检测。 - 非极大值抑制
细化梯度幅值图像,只保留局部梯度最大的点,去除非边缘的像素点。对于每个像素点,检查其梯度方向上的相邻像素点,如果当前像素点的梯度幅值不是最大的,则将其置为0。 - 双阈值检测
将边缘像素点分为强边缘、弱边缘和非边缘三类。设置两个阈值,高阈值 ( T_h ) 和低阈值 ( T_l )。梯度幅值高于 ( T_h ) 的像素点标记为强边缘,低于 ( T_l ) 的像素点标记为非边缘,介于两者之间的标记为弱边缘。 - 边缘跟踪与连接
连接强边缘和弱边缘,形成完整的边缘。遍历图像,如果一个弱边缘像素点与强边缘像素点8连通,则将其标记为边缘;否则,将其标记为非边缘。
- 高斯滤波
边缘连接和边界检测
- 局部处理
建立边缘像素相似性的主要性质:梯度向量的幅值和梯度向量的方向。
令 $S_{xy}$ 表示图像以点 $(x,y)$ 为中心的一个领域的坐标集。
$$ |M(s, t) - M(x, y)| \leq E $$
上式中,E 为正阈值,那么 $(s,t)$ 的边缘像素在幅值上和 $(x,y)$ 处的像素是相似的。
$$ |\alpha(s, t) - \alpha(x, y)| \leq A $$
上式中,A 为正阈值,那么 $(s,t)$ 的边缘像素在角度上和 $(x,y)$ 处的像素是相似的。
如果既满足幅度准则又满足方向准则,那么$(s,t)$ 的边缘像素连接到 $(x,y)$ 处的像素。 - 使用霍夫变换的全局处理
将图像空间中的点映射到参数空间,通过在参数空间中寻找局部最大值来检测特定的几何形状。- 边缘检测
首先对图像进行边缘检测,提取出图像中的边缘点。 - 构建参数空间
构建一个二维参数空间,维度为 $\rho, \theta$。对每个边缘点计算过该点的直线并在参数空间中进行累加。累加值表示有多少点落在该直线上。 - 统计累加器单元数量
在累加器空间中找到具有足够高累加值的峰值,其对应图像中的直线。 - 反变换
将参数空间中的峰值反变换回图像空间,得到检测到的直线在原始图像的位置。
- 边缘检测
阈值处理
基本的全局阈值处理
迭代算法:
- 为全局阈值选一个初始值 T
- 用 T 分割图像,灰度值大于 T 的所有元素组成 $G_1$,灰度值小于 T 的组成$G_2$。
- 分布对 $G_1$ 和 $G_2$ 计算平均灰度值 $m_1$ 和 $m_2$。
- 在 $m_1$ 和 $m_2$ 之间计算新的阈值 T
$$ T = \frac{1}{2}(m_1 + m_2)$$ - 重复步骤 2 到 4,直到连续迭代出来的两个 T 值小于某个预定义的值 $\Delta T$
Otsu:
Otsu 又称为大津法或最大类间方差法,大津法阈值采用最大类间方差的原理,适合于图像灰度分布整体呈现“双峰”的情况。大津法会自动找出一个阈值,使得分割后的两部分类间方差最大。具体步骤如下:
- 计算输入图像的归一化直方图。用 $p_i, i=0,1,2……L-1$ 表示直方图的各个分量
- 计算累积和 $ P_1(k)$
$$ P_1(k) = \sum_{i=0}^{k} p_i , k = 0,1,2……L-1$$ - 计算累积均值 $m(k)$
$$m(k) = \sum_{i=0}^{k} ip_i , k = 0,1,2……L-1$$ - 计算全局灰度均值 $m_G$
$$m_G = \sum_{i=0}^{L-1} ip_i$$ - 计算类间方差
$$\sigma_B^2(k) = \frac{[m_GP_1(k)-m(k)]^2}{P_1(k)[1-P_1(k)]}, k = 0,1,2……L-1$$ - 得到阈值 $k^*$,即使得 $\sigma_B^2(k)$ 最大的 k 值。如果不唯一,则将各个最大值 k 求均值。
- 计算全局方差 $\sigma_G^2$
$$ \sigma_G^2 = \sum_{i=0}^{L-1}(i - m_G)^2p_i$$
然后令 $k = k^*$ 来计算 $\eta$
$$\eta(k) = \frac{\sigma_B^2(k)}{\sigma_G^2}$$
改进全局阈值处理方法
- 平滑图像,减小噪声
- 利用边缘
- 对输入图像 $f(x,y)$ 计算梯度幅度或拉普拉斯的绝对值
- 规定一个阈值 T
- 使用 T 对步骤一中的图像进行阈值处理得到 $g_T(x,y)$ 作为模板图像。其选择了强边缘像素。
- 只使用 $f(x,y)$ 中对应 $g_T(x,y)$ 的像素位置计算直方图
- 使用步骤四中的直方图分割图像 $f(x,y)$
多阈值处理
可变阈值处理
图像分块
可变阈值处理最简单的处理方式之一就是把一幅图像分成不重叠的矩形,这种方法用于补偿光照或反射的不均匀性。选取的矩形要足够小,以便每个矩形的光照都是近似均匀的。基于局部图像特性的可变阈值处理
与上面的方法相比,更为一般的方法是在一幅图像的每个点 $f(x,y)$ 计算阈值。标准差和均值对于求局部阈值很有用,因为他们是对比度和平均灰度的描述子。- 标准差表示图像中明暗变化程度,标准差越大,表示图像中明暗变化越明显。
- 均值可以用于表示图像整体的亮暗程度,图像的均值越大,图像整体越亮。
令 $m_{xy}$ 和 $\sigma_{xy}$ 是图像中以 $(x,y)$ 为中心的邻域包含的像素集的标准差和均值。
$$ T_{xy} = a\sigma_{xy} + bm_{xy} $$
其中,a 和 b 是非负常数,分割后的图像计算
$$ g(x,y) = \begin{Bmatrix} 1, f(x,y)>T_{xy} \ 0, f(x,y) \leq T_{xy}\end{Bmatrix}$$基于移动平均的可变阈值处理
移动平均法通过计算每个像素点周围邻域内的灰度平均值,并将其作为该像素点的阈值。具体步骤如下:- 定义邻域大小:首先确定每个像素点的邻域大小,通常是一个矩形窗口(如3x3、5x5等)
- 计算移动平均值:对于图像中的每个像素点,计算其邻域内的灰度平均值。
- 确定阈值:将计算得到的移动平均值作为该像素点的阈值
基于区域的分割
区域生长
区域生长是一种基于区域的图像分割技术,其基本思想是从一个或多个种子点开始,逐步将与其相似度高的邻接像素合并到当前区域中,直到满足某种停止条件为止。这种方法适用于分割具有相似特征的连通区域,广泛应用于医学图像处理、遥感图像分析等领域。
- 选择种子点:在图像中选择一个或多个初始种子点,这些点通常位于感兴趣区域的内部。
- 定义相似性准则:设定一个相似性准则,用于判断邻接像素是否应被合并到当前区域。常见的准则包括灰度值差异、纹理特征等。
- 区域生长:从种子点开始,逐步将满足相似性准则的邻接像素合并到当前区域。
- 停止条件:设定一个停止条件,如区域达到一定大小、没有更多满足条件的像素等。
区域分裂与聚合
区域分裂与聚合是一种基于区域的图像分割技术,其核心思想是通过递归地分裂和合并图像区域来实现分割。
- 区域分裂:将图像划分为更小的区域,通常使用四叉树分裂方法。如果一个区域不满足某种均匀性准则(如灰度值差异较大),则将该区域进一步分裂成更小的子区域。
- 区域聚合:在分裂过程中或分裂完成后,检查相邻区域是否满足某种相似性准则(如灰度值相似),如果满足则将它们合并成一个更大的区域。
通过交替进行分裂和聚合操作,最终得到满足分割条件的区域。
使用聚类和超像素的区域分割
聚类
K-means
K-means 聚类是一种无监督学习算法,广泛应用于图像处理中的分割、压缩和特征提取等任务。其核心思想是将图像中的像素点划分为 $ k $ 个簇,使得每个簇内的像素点在特征空间中尽可能接近其簇中心(质心),而不同簇之间的像素点差异显著。
K-means 聚类算法的基本原理如下:- 初始化:随机选择 $ k $ 个数据点作为初始的簇中心。
- 分配簇:将每个数据点分配到最近的簇中心,形成 $ k $ 个簇。
- 更新簇中心:重新计算每个簇的中心,即计算簇内所有点的均值作为新的簇中心。
- 迭代:重复步骤2和步骤3,直到簇中心不再变化或达到最大迭代次数。
优点:
- 简单高效:算法实现简单,计算效率高。
- 适用于大数据:能够处理大规模数据集。
- 直观:聚类结果易于理解和解释。
缺点:
- 对初始质心敏感:聚类结果依赖于初始质心的选择,不同的初始质心可能导致不同的结果。
- 需要预先指定簇的数量:需要事先确定 $ k $ 的值,不合适的 $ k $ 可能导致不理想的聚类效果。
- 难以处理非凸形状的簇:对于非凸形状的簇,K-means 可能无法得到准确的聚类结果。
超像素
基于超像素的区域分割是一种常用的图像处理技术,旨在将图像分割成若干个超像素(Superpixels),每个超像素是一个具有相似特征的小区域。超像素分割可以简化图像的表示,减少后续处理的数据量,同时保留图像的主要结构信息,广泛应用于图像分割、目标检测、图像理解等领域。
超像素分割的基本思想是将图像中的像素点按照一定的相似性准则(如颜色、纹理、空间位置等)聚集成若干个小区域,每个小区域称为一个超像素。通过超像素分割,可以将图像从像素级别简化到超像素级别,从而降低后续处理的复杂度。
形态学分水岭分割图像
形态学分水岭分割是一种基于形态学的图像分割技术,其灵感来源于地理学中的分水岭概念。分水岭分割将图像视为地形图,其中像素的灰度值代表海拔高度。通过模拟水从局部最小值开始流动并汇聚成河流的过程,算法能够找到不同像素区域之间的边界,尤其擅长捕捉微弱边缘并生成封闭、连续的分割结果。
分水岭算法的整个步骤:
- 把梯度图像中的所有像素按照灰度值进行分类,并设定一个测地距离阈值。
- 找到灰度值最小的像素点(默认标记为灰度值最低点),让threshold从最小值开始增长,这些点为起始点。
- 水平面在增长的过程中,会碰到周围的邻域像素,测量这些像素到起始点(灰度值最低点)的测地距离,如果小于设定阈值,则将这些像素淹没,否则在这些像素上设置大坝,这样就对这些邻域像素进行了分类。
- 随着水平面越来越高,会设置更多更高的大坝,直到灰度值的最大值,所有区域都在分水岭线上相遇,这些大坝就对整个图像像素的进行了分区。
分割中运动的使用
空间域
- 基本方法
检测在时刻 $t_i$ 和 $t_j$ 得到的两幅图像之间的变化的最简方法之一,是逐像素比较这两幅图像。
在 $t_i$ 和 $t_j$ 获取的两幅图像间的差值图像定义为:
$$ d_{ij}(x,y) = \begin{Bmatrix} 1, |f(x,y,t_i)-f(x,y,t_j)|>T \ 0,其它\end{Bmatrix}$$
仅当两幅图像的灰度差在 $(x,y)$ 处明显不同时,$d_{ij}(x,y)$ 在该处的值才为 1. - 累积差值
累积差值图像(ADI):通过将参考图像与序列中每幅后续图像进行比较形成的。有绝对ADI、正ADI、负ADI三种类型。
当参考图像和序列中一幅图像之间在某个像素位置上出现一次差异时,累计图像中每个像素位置的计数器计数一次。 - 建立参考图像






