
图像模式分类
图像模式分类
原型匹配模式分类
原型匹配涉及将一个未知的模式与一组原型相比,并将一个原型类赋予这个未知的模式,当然这个原型类是与未知模式最相似度。每个原型表示一个独特的模式类,但每个类可能有多个原型。区分不同匹配方法的是用于确定相似性的测度。
最小距离分类器
原型匹配模式分类中的最小距离分类器(Minimum Distance Classifier)是一种简单而直观的分类算法,广泛应用于图像处理和模式识别领域。其核心思想是通过计算待分类样本与各个类别原型(即类别中心)之间的距离,将样本归类到距离最近的类别中。
- 最小分类器的原型向量通常是各个模式类的平均向量
$$ m_j = \frac{1}{n_j}\sum_{x \in c_j}^{} x ,\ \ \ \ \ \ \ \ \ j = 1,2…N_c$$
式中 $N_c$ 表示类数,$n_j$ 是用于计算第 $j$ 个平均向量的模式向量数, $c_j$ 是第 $j$ 个模式类 - 欧氏距离求相似性,最小分类器计算距离
$$D_j(x) = ||x-m_j||,\ \ \ \ \ \ \ \ \ j = 1,2…N_c$$ - 选择最小距离等于计算如下函数
$$ d_j(x) = m_j^Tx - \frac{1}{2}m_j^Tm_j $$ - 最小距离分类器的决策边界
$$ d_{ij}(x)=d_i(x)-d_j(x)= (m_i-m_j)^Tx - \frac{1}{2}(m_i-m_j)^T(m_i+m_j)$$ - 例1
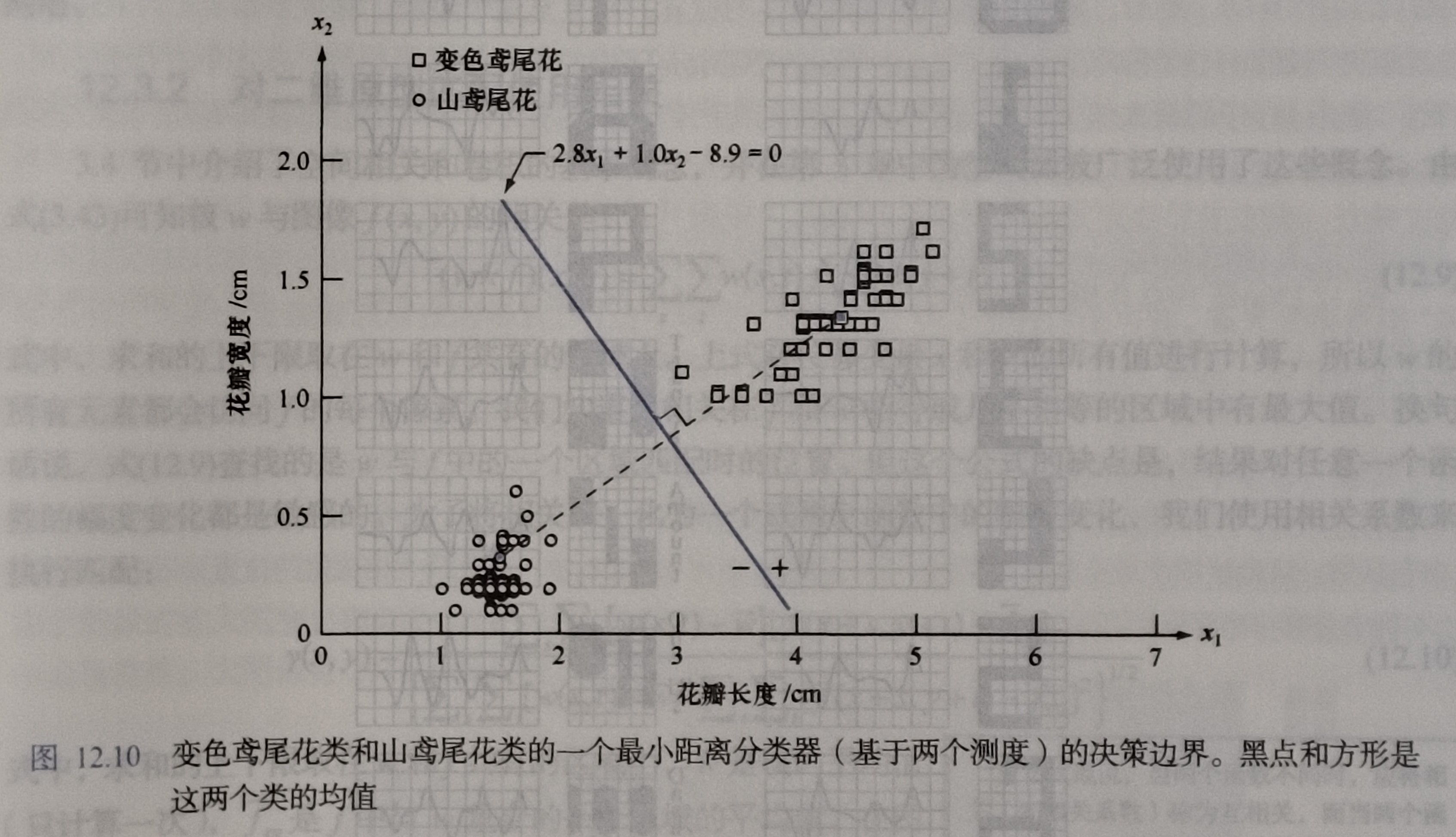 变色鸢尾花类和山鸢尾花类数据分别为 $c_1$ 和 $c_2$,他们的均值分别是$m_1=(4.3,1.3)^T$ 和 $m_2=(1.5,0.3)^T$,可以得到:
$$ d_1(x) = m_1^Tx - \frac{1}{2}m_1^Tm_1=4.3x_1+1.3x_2-\frac{1}{2} \times 4.3^2 \times 1.3^2$$
$$ d_2(x) = m_2^Tx - \frac{1}{2}m_2^Tm_2=1.5x_1+0.3x_2-\frac{1}{2} \times 1.5^2 \times 0.3^2$$
得到边界的公式为:
$$ d_{12}(x) = d_1(x) - d_2(x) = 2.8x_1 + 1.0x_2-8.9=0 $$
来自 $c_1$ 类的数据带入上式得到 $d_{12}(x) > 0$。相反,来自 $c_2$ 类的数据带入上式得到 $d_{12}(x) < 0$.如果有一个未知模式 $x$ 属于这两类,只需要带入式子,$d_{12}(x)$ 的符号可以确定类别。
变色鸢尾花类和山鸢尾花类数据分别为 $c_1$ 和 $c_2$,他们的均值分别是$m_1=(4.3,1.3)^T$ 和 $m_2=(1.5,0.3)^T$,可以得到:
$$ d_1(x) = m_1^Tx - \frac{1}{2}m_1^Tm_1=4.3x_1+1.3x_2-\frac{1}{2} \times 4.3^2 \times 1.3^2$$
$$ d_2(x) = m_2^Tx - \frac{1}{2}m_2^Tm_2=1.5x_1+0.3x_2-\frac{1}{2} \times 1.5^2 \times 0.3^2$$
得到边界的公式为:
$$ d_{12}(x) = d_1(x) - d_2(x) = 2.8x_1 + 1.0x_2-8.9=0 $$
来自 $c_1$ 类的数据带入上式得到 $d_{12}(x) > 0$。相反,来自 $c_2$ 类的数据带入上式得到 $d_{12}(x) < 0$.如果有一个未知模式 $x$ 属于这两类,只需要带入式子,$d_{12}(x)$ 的符号可以确定类别。
相关匹配
图像相关系数归一化是一种用于衡量两幅图像相似度的方法,通过归一化处理,消除图像灰度水平和对比度差异的影响,从而更准确地反映图像之间的相似性。
假设有两幅灰度图像 $I$ 和 $J$,大小都为 $M×N$,图像 $I$ 和 $J$ 的像素值分别为 $I(x,y)和 J(x,y)$,其中 $x$ 和 $y$ 是像素坐标。
- 计算图像的均值:
$$ \bar{\mu}_i=\frac{1}{MN} \sum_M \sum_N I(x,y) $$
$$ \bar{\mu}_j=\frac{1}{MN} \sum_M \sum_N J(x,y) $$ - 计算图像的方差:
$$ \sigma_i^2 = \frac{1}{MN}\sum_M \sum_N [I(x,y)-\bar{\mu}_i]^2 $$
$$ \sigma_j^2 = \frac{1}{MN}\sum_M \sum_N [J(x,y)-\bar{\mu}_j]^2 $$ - 计算图像的协方差:
$$ \sigma_{ij} = \frac{1}{MN}\sum_M \sum_N [I(x,y)-\bar{\mu}_i][J(x,y)-\bar{\mu}_j] $$ - 计算归一化相关系数:
$$ \gamma(x,y) = \frac{\sigma_{ij}}{\sqrt{\sigma_i^2\sigma_j^2}} $$
归一化相关系数 $\gamma(x,y)$ 的取值范围在 $[-1,1]$
- $\gamma(x,y) = 1$ 表示两幅图像完全正相关
- $\gamma(x,y) = -1$ 表示两幅图像完全负相关
- $\gamma(x,y) = 0$ 表示两幅图像不相关
最优(贝叶斯)统计分类器
贝叶斯统计分类器在图像处理中是一种非常有效的工具,它基于贝叶斯定理,通过概率模型来进行图像的分类和识别。
- 贝叶斯定理
$$ P(A|B) = \frac{P(B|A)P(A)}{P(B)} $$- $P(A|B)$ 是在事件 B 发生的情况下事件 A 发生的概率。
- $P(B|A)$ 是在事件 A 发生的情况下事件 B 发生的概率。
- $P(A)$ 是事件 A 发生的先验概率。
- $P(B)$ 是事件 B 发生的总概率。
优点:
- 简单高效:具有较低的计算复杂度,实现和计算都比较简单,适合大规模数据集。
- 性能优异:在高维数据上表现良好,尤其是在文本分类中。
缺点:
- 独立性假设:朴素贝叶斯分类器的独立性假设在实际应用中往往不成立,可能在某些情况下产生错误的分类结果。
- 数据稀疏性:对于稀疏数据,计算条件概率可能会出现零概率问题,需要使用拉普拉斯平滑等技术。
神经网络与深度学习
卷积神经网络CNN
卷积神经网络是一种深度学习模型,通常用于处理具有网络结构数据的任务,如图像和视频处理。- 卷积层:输入数据通过一个或多个卷积层,每个卷积层包含多个滤波器(卷积核),他们扫描输入图像并提取特征。滤波器的权重是需要通过训练学习得到的。卷积操作产生特征图,这些特征图捕捉输入数据中的空间结构信息。
- 激活函数:在卷积层后,通常会应用激活函数,如ReLU,用于引入非线性特性。
- 池化层:池化层用于减小特征图的空间尺寸,同时保留重要信息。常见的池化操作包括最大池化和平均池化。
- 全连接层:在经过一系列的卷积层和池化层后,数据被展平并输入到全连接层。全连接层的神经元与前一层中的所有神经元相连接。
训练CNN反向传播步骤
- 正向传播:首先通过正向传播,将训练数据送入卷积神经网络,一直传播到输出层,生成模型的预测,记录每个层的中间输出,因为这些输出将在反向传播中用到。
- 计算损失函数:使用预测的输出和实际目标之间的差异来计算损失。
- 反向传播误差:从输出层开始,计算损失函数对网络参数的梯度。通过链式法则来计算,将误差从输出层传播到隐藏层。
- 参数更新:使用梯度下降来更新每个参数。梯度方向告诉我们应该增加还是减少参数的值,更新的步长有学习率的控制,学习率决定了每次参数更新的大小。
- 重复迭代:重复进行上面四个步骤,通过多次迭代,直到损失足够小或模型收敛到满意的性能。
- 测试和验证:训练过程中,通常会分为训练集、验证集和测试集,以监控模型的性能。验证集用于调整参数,测试集用于评估模型的最终性能。
CNN和全连接神经网络的区别
- CNN输入的是二维阵列,全连接神经网络输入的是向量。
- CNN可以直接由原图像学习二维特征。
- 各层的连接方式。全连接神经网络中,将一层中每个神经元的输出直接馈送到下一层中每个神经元的输入;在CNN中,将单个值馈送一层的每个输入,这个值是上一层输出中的一个空间领域上的卷积,因此CNN不是全连接的。
- CNN从一层到下一层的二维阵列被子取样。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Star!






